法安网内容检索
法安网内容检索
.jpg)
.jpg)
.jpg)

当前位置: 首页 > 产品方案 > 方案展示 > AI大模型 >
时间:2025-10-20 13:34:51 来源:陆永 罗丹 周攀锋 钟浩翔 钟微宇 佛山市公安局科信支队
[法安导读]【摘 要】:视觉大模型是当下人工智能研究和应用的重要热点之一,其在各行业的应用正在逐步铺开,在智慧公... 

【摘 要】:视觉大模型是当下人工智能研究和应用的重要热点之一,其在各行业的应用正在逐步铺开,在智慧公安领域的应用潜力巨大。本文简介了视觉大模型的背景和优势,提出建设智慧公安视觉大模型的建设架构,为公共安全行业大模型建设应用提供参考借鉴。
【关键词】:视频图像、大模型、智能应用、智慧警务
随着“雪亮工程”、平安城市等政策和重大项目落地实施,人工智能等新技术在公安部门得到大力支持和大规模应用。AIGC(人工智能生成内容,AI Generated Content)是人工智能大模型产学研用的重要发展分支,以ChatGPT(主要功能文本生文本)、DALL-E(主要功能文本生图片)、Sora(主要功能文本生视频)为代表的AIGC问世掀起了大模型风投、研发和应用热潮,ChatGPT、Sora几度全网霸屏、头条热议。AIGC在侦查破案、文书处理、指挥决策等13项警务工作中有重要应用,提高工作效率和质量。视觉大模型作为AIGC的研究应用热点之一,模拟人眼和人脑处理视觉信息的机理和过程,目标定在“世界模拟器”,理解认知视频图像数据大部分内容,其在公共安全视频图像智能化应用方面备受关注和瞩目。
一、视觉大模型优势
视觉大模型通过从海量的、多类型的数据中总结学习不同场景业务下的通用特征和规则,成为具有泛化能力的模型底座,能解决传统视频图像智能化建设的高成本、低效率、难更新等问题。
(一)要素全量采集,解决视图信息提取不全的弊
传统的智能识别算法仅能提取高质量的人像、车辆目标或非机动车目标,而图像中的大量关注信息无法捕获和解析,海量的视频数据处于沉睡休眠状态而未被开发应用。而视觉大模型能够对视频流和图片流中的感兴趣区域和目标进行全量准确捕捉,实现视频图像数据信息密度从低价值向高价值提纯。
(二)目标准确关联,弥补兴趣对象分割孤立的不足
传统视图智能应用仅限于单类目标的准确识别比对,无法找出视频图像数据中的人人关系、人车关系、车车关系等重要关联关系,事物之间自有的普通联系内在属性被技术化割断,造成目标对象孤立,极大制约情报信息研判效率。而视觉大模型不仅能对图像语义完整提取,还能对感兴趣目标精准关联,对同类目标或同一目标进行关联化,如人车关联、人物关联、六同关系等。
(三)能力泛化通用,克服应用场景单一严苛的弱点
目前在用的视图智能应用系统对摄像机参数、建设质量、布建环境、安装调试、应用场景等有严格的技术标准和规范,视频应用、车辆应用、非机动车应用、人脸应用、视频结构化五大类系统建设割裂、系统林立,相关算法缺乏通用性且仅用于特定场景,存在对公安实战中复杂场景的泛化能力明显不足、识别精度低的先天缺陷。而视觉大模式具有非常强的泛化性和鲁棒性,针对低照度、宽动态、超广角、高模糊等场景中采集的视频图像数据进行高效处理,轻松突破应用场景的限制和智能应用不足的短板。
二、建设技术架构
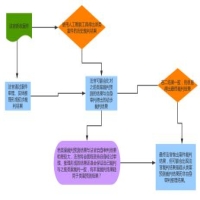
结合信创政策法规、政务信息化发展方向、公安视频图像智能化建设应用趋势,坚持“集约建设、共享共用、分层解藕、合理利旧、模块部署、自主可控”原则,总体技术架构为“六横四纵”,“六横”指感知层、网络层、基础层、模型层、应用层、交互层,“四纵”指标准体系、安全保障、运行管理、法规政策。
")
图 视觉大模型技术架构
(一)“六横”构成
1.感知层:
由立体化、网络化、智能化高清摄像机构成,含枪型、球型、枪球一体摄像机和移动式摄像机,主要负责采集高清的图片、视频或与视频图像相关的结构化数据,实时无感采集公安关注人员、车辆、物体、事件、场所、行为等要素,是算据的主要来源。
2.网络层:
由各类视频图像采集网(视频专网、电子政务外网、视联网等)、VPN或互联网、接入网关、转换网关、安全设备等组成,是视图数据传输的“高速公路”,主要负责前端各类摄像机所采集数据的高速率、低时延、零差错安全传输和跨网摆渡,为点多面广、零散分布的视图数据联网整合和统一汇聚提供通道。
3.基础层:
由算力、算据、算法三大核心资源组成,是大模型运行和应用的基石。其中算力资源由各类服务器、存储设备和网络安全设备、云平台、操作系统等构成,经云化后提供各类虚拟机或裸金属物理机、云存储、云网络、云安全等基础云服务,为大模型提供安全可信、自主可控的基础运行环境。算据资源是视频图像数据集,由各类摄像机采集的视频图像数据、结构化数据、大数据平台服务数据、其他渠道采集的视频图像数据(如涉案视图库)构成,图片类及结构化数据由视频图像信息数据库提供,视频流数据由视频联网平台提供。算法资源由各类目标识别分析算法、算法框架、开发平台等构成,是人车物智能识别和综合应用的核心部分。
4.模型层:
由预训练视觉大模型和开源社区模型提供支撑服务,经特定的数据处理、模型开发、调优、训练后演化为基础视觉大模型,可提供智能识别、推理判断、模型服务等功能。公安在长时间的图侦工作中累积了丰富的涉案视图库和大量的标签数据,注重收集、梳理、归类历年涉案视频图像数据和标签数据,并进行准确的标记,用来作为模型训练的数据集,精准投喂大模型,不断提升模型对视频图像理解识别能力和预测预警准确性。
5.应用层:
由基础应用、警务应用场景和警种专属模型三大部分构成,基础应用提供目标对象的智能检索服务(如以图搜图、特征检索、模糊检索、语音搜索等)、预测预警、目标识别比对等,具备自定义检索、全要素比对、全时空轨迹回溯、全过程行为分析、人案车案关联分析等高阶智能应用;警务应用场景涵盖警务实战应用中的各类实战场景,提高打击违法犯罪、维护政治安全和社会稳定、维护交通安全和交通秩序、特行监管、服务人民的工作效能;警种专属模型是结合各警种的具体业务需求和警种自身业务数据,在基础视觉大模型的基础上进一步训练优化,升级为警种专用模型,提供专业化、特色化、个性化的智能应用。
6.交互层:
由国产终端(PC)、警务移动终端、智能屏、监控屏组成,提供客户端、App、网页版等多形式的人机交互媒介,具备良好的人机交互界面,可通过文字、语音、图片、视频、触摸等方式输入信息,快速输出视图高价值情报信息。
(二)“四纵”构成
1.标准体系:
由基础共性标准、支撑标准、关键技术标准等6部分标准构成,标准先行,指导视觉大模型规划、建设、应用、管理和应用工作。
2.安全保障:
由安全管理、管理制度、技术防护等组成,构建起视觉大模型全生命周期的纵深安全防护体系,提高应用的安全性。
3.运行管理:
由资源管理、训练任务管理、模型管理等组成,通过成套成成体系的运行管理制度,形成完善的运营运维管理机制,提高视觉大模型运行的稳定性、可靠性和安全性。
4.法规政策:
由法律法规、行政规章、方针政策等组成,引导和规范视觉大模型高质量发展。
三、结语
视觉大模型非常擅长高效捕获视频图像中相关目标对象,并能推理现实世界的各种联系,对视频图像具有强大的理解和认知能力,助推警务工作通过视觉感知、推理、预测做出精准情报研判和科学决策,能极大提升公共安全保障能力和社会治理的智能化水平。同时也要清醒看到视觉大模型带来的信息安全、隐私保护、伦理法律等问题,如深度伪造的视频图像数据对公共安全视频图像数据客观性、真实性造成巨大挑战。因此要对新技术始终坚持审慎包容态度,加强产业规划设计、法规政策研究、标准规范制定、行业监管执法,引导规范视觉大模型高质量发展,为智慧公安跨越式发展提供厚实技术支撑。
责任编辑:广汉
声明:
本网站图片,文字之类版权申明,因为网站可以由注册用户自行上传图片或文字,本网站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。

征稿启事

投稿信箱:195024562@qq.com
品牌推荐更多>>

.jpg)
.jpg)



版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号