法安网内容检索
法安网内容检索
.jpg)
.jpg)
.jpg)
.jpg)
时间:2019-04-12 17:20:33 来源:
[法安导读] 按照公安部2004年《居民身份证制证用数字相片技术要求》规定,居民身份证照片除了要求免冠以及纯白... 

按照公安部2004年《居民身份证制证用数字相片技术要求》规定,居民身份证照片除了要求免冠以及纯白背景以外,还有严格的标准要求,如头部占照片尺寸2/3,照片尺寸为26mm(宽)×32mm(高),脸部宽度(两耳根之间)为15±1mm这就意味着,身份证照片中的人在整个图片中的位置,以及脸部、耳部等特征点的分布区域也是基本一致的。与此不同的是,采集的照片却有大头照、半身照、全身照,甚至是模糊照片、“空镜头"等没有人像的情况。
鉴于上述因素及图片灰度直方图分析法对证件照片加入噪声、对图片进行遮盖过于敏感及对曝光过度误筛选的弊端,通过引入SIFT特征采集对图片灰度直方图分析法特征进行扩展,可有效解决上述弊端。
SIFT(Scale-lnvariant Feature Transform)即尺度不变特征转换,SIFT特征向量提取算法是由David Lowe在1999年所发表,2004年完善总结。SIFT阿是一种电脑视觉的算法,基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关,对光线、噪声的容忍度也相当高。基于这些特性,在采集图片特征库样本相对比较庞大的数据中,很容易辨识物体而且误识别度很低。
SIFT算法实质是在不同尺度空间上查找关键点,并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照、放射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
对图片进行阿特征提取步骤,如图3所示
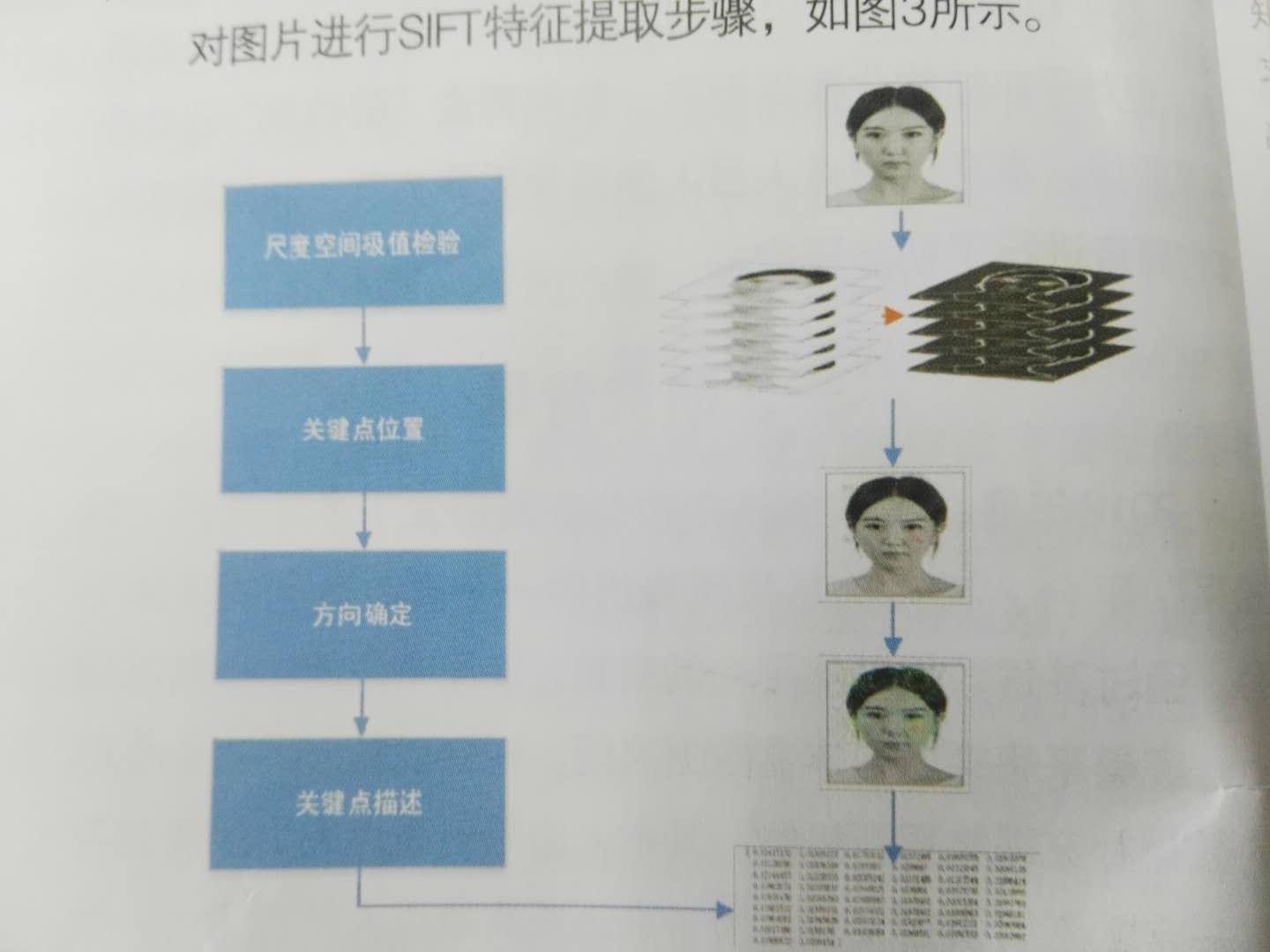
第一步是构建尺度空间。这是一个初始化操作,目的是模拟图像数据的多尺度特征,为最终的特征提取做基础;
第二步是尺度空间极值监测。搜索所有尺度的图像位置,通过高斯微分函数来识另刂潜在的对于尺度和旋转不变的兴趣点;
第三步是对关键点进行定位。在每个候选位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择体据于它们的稳定程度;
第四步是关键点方向确定。基于图像的局部梯度方向,分配给个关键点位置一个或多个方向。后续的还对图像数据的操作都是相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性;
第五步是关键点描述。在每个关键点周围的领域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种规律表示,这种表示允许图像发生比较大的局部形状的变形或者光照变化。
在本例中采用SIFT聚类的方法筛查问题图片,如图4所示,需要将RGB直方图特征及SIFT特征提取的结果通过K_means、SVM模型训练,实现对采集照片的有效筛查。
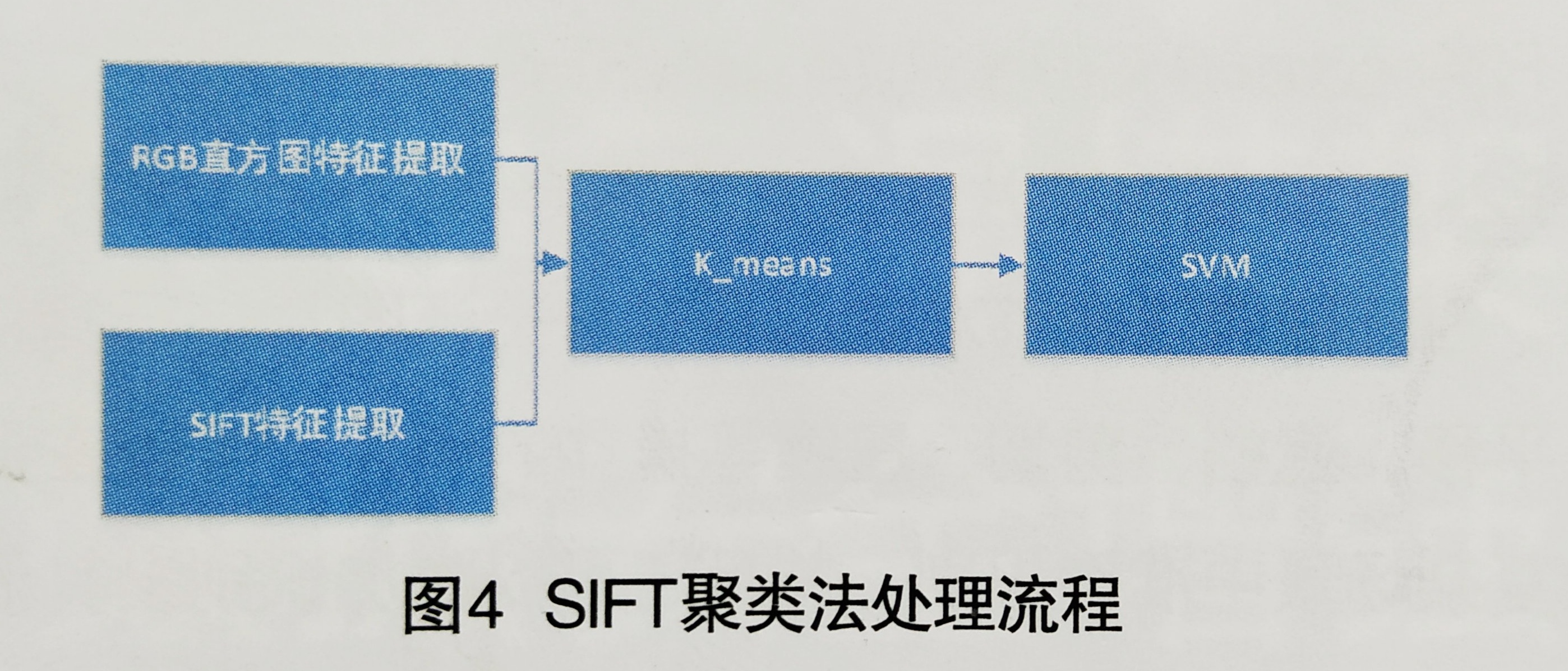
1,特征拼接
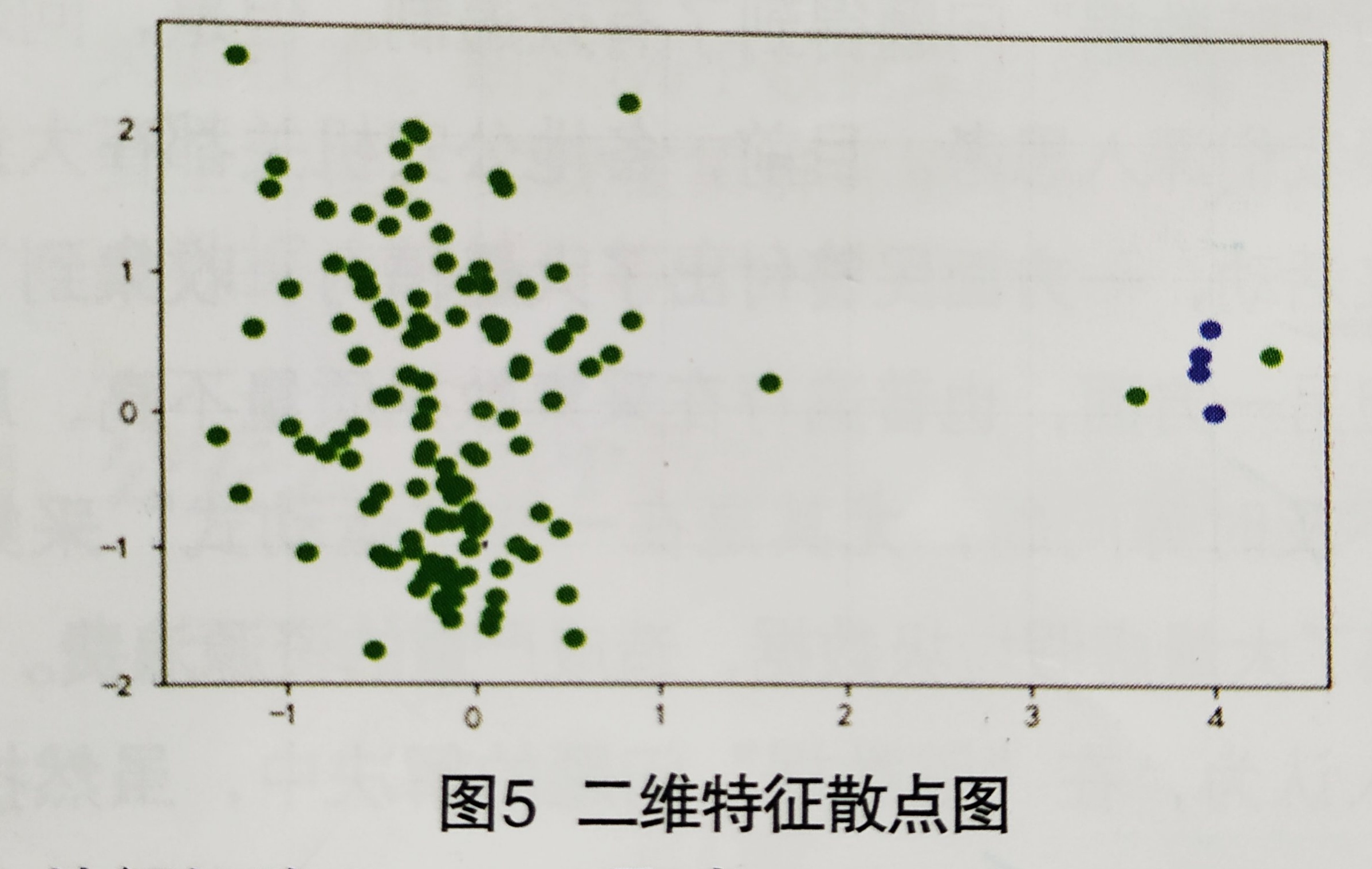
将图片直方图分析法特征及SIFT特征提取的两个特征矩阵进行矩阵拼接,构建整体机器学习特征矩阵。将机器学习特征矩阵通过A得到二维特征散点图(图5),可以看出合格图片的特征数据有一定的聚集性。
2.特征矩阵K_means聚类
聚类算法在数据挖掘领域中是一项非常重要的技术,可以描述大量数据的数据分布状况,而且可以发现数据中所藏的规律。人像采集分类流程一般分为建立特征矩阵、K-means聚类、聚类结果分析、聚类结果评估验证、策略应用模型选取及图像类别特征构建这几个步骤。
(1)K-means算法聚类
用K-means算法进行聚类分析,最重要的两个参数是最大分类的个数K以及K个初始凝聚点的选择。K值的选择可根据行业经验值,聚类生成K个图像组。其基本步骤如下:
步骤1,确定K值以及初始化聚类中心,选择K个初始凝聚点作为欲形成类的中心;
步骤2,计算每一个观测到K个初始凝聚点的距离,将每个观测和最近的凝聚点分到一组,形成K个初始分类;
步骤3,计算初始分类的中心(或均值),作为新的凝聚点,重新计算每一个观测到初始分类中心的距离,将每个观测和最近的凝聚点分为一组;
步骤4,重复进行步骤2和步骤3,直至初始分类的中心或均值没有明显变化为止。
K-means算法以最小化类内残差平方和Ek为收敛准则,当Ek不再变化或变化不明显的时候,停止迭代。
(2)聚类结果分析
在确定了最终聚类个数,并选择最小的类内残差平方和的聚类方案之后,需要对聚类结果进行解释。如果能满足业务需求或者解决了业务问题,则为一个好的模型方案,否则需要返回重新聚类,迭代进行,直至取得较为理想的结果。
(3)聚类结果评估验证
为验证K-means聚类的结果,采用其他算法对同样的数据进行聚类,通过两种聚类结果的比较,验证两种聚类算法结果的一致性。如果两种算法结果的一致性很好,即可验证聚类结果的稳定性和有效性。
(4)模型应用策略选取
通过执行聚类分析,将图像进行分组,并对聚类结果进行评估,选出技术上效果最好的几种方案作为备选。将照片用聚类分析分到不同的组后,需要对不同组的图像特征进行概括和归纳,归纳每一个分组内图像的共同特征,从业务角度看图像的分组结果是否有意义,并从中选出最好的一个方案作为最终细分方案。
(5)图像类别特征构建
将选取的最优K-means分类模型应用到人像采集库,对图像进行分类计算,将类别信息及特征矩阵数据拼接成最终特征数据矩阵。
3.SVM
利用特征矩阵数据及类别信息,利用支持向量机(SVM)进行分析训练,训练后的模型直接用于生产,进行实时判断采集照片是否合规。
声明:
本网站图片,文字之类版权申明,因为网站可以由注册用户自行上传图片或文字,本网站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。

征稿启事

投稿信箱:195024562@qq.com
品牌推荐更多>>

.jpg)
.jpg)



版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号











