法安网内容检索
法安网内容检索
.jpg)
.jpg)
.jpg)
.jpg)
时间:2025-03-14 14:16:43 来源:
[法安导读]以下推出的是《智慧检务篇 | 创新经验之“用法律逻辑解构司法业务数据为监督模型提供规则”》 

为深化政法智能化建设,加强“智慧治理”“智慧法院”“智慧检务”“智慧警务”“智慧司法”等信息平台建设,深入实施大数据战略,实现科技创新成果同政法工作深度融合。法制日报社已连续举办了七届“政法智能化建设技术装备及成果展”。
作为装备展配套活动,法制日报社于2024年3月继续举办了2024政法智能化建设创新经验征集宣传活动,活动征集了“智慧治理”“智慧法院”“智慧检务”“智慧警务”“智慧司法”创新经验。
在2024年7月10日至11日举办的成果展上,对入选的创新经验进行了集中展示,并已编辑整理成册——《2024政法智能化建设创新经验汇编》。
该汇编分为智慧治理篇、智慧法院篇、智慧检务篇、智慧警务篇、智慧司法篇五个篇章,为政法信息化、智能化建设提供及时、准确、 实用的资讯信息与经验观点。
应广大读者要求,我们特开辟专栏,将部分创新经验进行展示,敬请关注!
以下推出的是《智慧检务篇 | 创新经验之“用法律逻辑解构司法业务数据为监督模型提供规则”》

用法律逻辑解构司法业务数据为监督模型提供规则
王 珣 江苏省泰州市海陵区人民检察院
王玎飏 南京财经大学会计学院
【摘 要】以法律逻辑为途径或方法,将法律法规条文转化为比较接近计算机语言的逻辑范式,为大数据建模提供准确规范的依据。即运用法律逻辑学的方法,分析有关法律规定,通过准确认定法律概念,运用真值表、命题转换等方法规范处理各类命题,从而将提炼出的逻辑范式与业务数据做到完全对应,并通过计算机技术运用到监督模型之中,可以实现对业务数据的分析,并以此拓展到类案线索的挖掘。该研究的价值在于,其并不拘泥于通过新的办案工作发现某一项或一块具体的大数据监督线索,而是探索如何构建普遍适用的刑事司法大数据规则,即研究提炼监督规则的方法。
【关键词】法律逻辑;大数据;监督模型;ChatGPT
“用法律逻辑解构司法业务数据”就是以法律逻辑为途径或方法,在解析法律法规条文的基础上,结合或针对已有的司法业务数据,通过科学构造,转化为无缝衔接计算机语言的规范逻辑关系真值表,再利用检察机关的法律监督模型平台等计算机软件直接吸收为规则,在分析真实的业务数据后,即可以高效的实现法律监督。
一、运用法律逻辑学的有关理论和方法,分析法律规定,通过准确认定法律概念,运用真值表、命题转换等方法规范处理各类法律命题,得到以下两方面的内容。
(一)数据项,即要采集、分析什么数据。
笔者认为,司法办案流程种类之复杂、数据项之丰富,远超普通行业。毕竟法律规定是社会经验的总结,案件事实又千变万化,客观无争议的概念仅占其中极小一部分,而大量存在的都是主观性强、外延宽广的概念、描述。目前不可能也没必要对法律所涉及的全部要素通过数据化、信息化的方式来进行采集。如:刑事诉讼法所规定的“情节显著轻微”,其具体类型,显然不可用信息化手段来采集,因为逻辑上这个概念的内涵小,而外延大,完全不能用罗列的方式来设计所谓的“数据项”。而对于确定需要数据化采集的项目,我们也应当准确认定法律概念,在设计时予以精准和细化,应秉持内涵大、外延小的原则来确定数据项,避免数据填录、收集时的问题。只有这样,才能将法律要素科学的转化为数据项,纳入相关系统设计的架构之中,最终成为司法业务数据库中的有效数据。
如:根据《刑事诉讼法》第一百七十八条,“不起诉的决定,应当公开宣布,并且将不起诉决定书送达被不起诉人和他的所在单位”,可以设计“是否不起诉”、“是否送达被不起诉人”、“是否送达被不起诉人所在单位”等数据项。但在设计“是否不起诉”项目时,如不去细化区分不起诉中的各种情形(有的情形并不适用),就会导致在日后的分析时会出错。
如果不能科学精准的开展确定数据项工作,可能出现以下问题:
1.相关业务系统中虽然设计了数据项,但无法实现自动抓取,而人工填录时又极难理解或者学习、甄别成本极高。这样的数据项,因无法准确填录,即使采集到了数据也是不准确的。笔者认为,如果一个数据项所采集的20%以上的数据都不准确,等同于无效数据。因为大数据技术的理念中,尽管应忽视不准确或错误的少部分数据,可以接受“瑕不掩瑜”,但绝对不可能适应“泥沙俱下”;
2.在开展大数据法律监督工作时犯理想主义或经验主义错误。如上所举的例子,将“情节显著轻微”的具体情形采集为数据项,以实现司法办案中对绝对不起诉的简单判断,这显然是做不到的。因此,在谋划、构造具体的大数据法律监督工作时,若不去科学全面分析数据项的设计与采集工作,就会走弯路,甚至要在投入了一定的人力、物力、时间成本以后,才发现“舞台搭建好了,却找不到演员”。
(二)(与法律法规对应的)准确、全面的(以数据项为项目的)逻辑关系真值表。
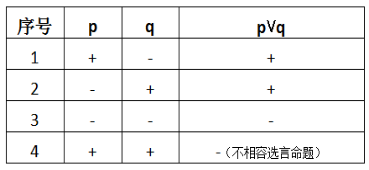
确定了数据项以后,要从已有的法条提炼一条有效的规则并不简单,即使是看起来很简单的法条。而当我们从实体法、程序法等所内涵的法律逻辑角度,用真值表来进行分析,发现说的通、行得通、可预见。如:《刑事诉讼法》第六十八条 人民法院、人民检察院决定对犯罪嫌疑人、被告人取保候审,应当责令犯罪嫌疑人、被告人提出保证人或者交纳保证金。通过真值表对法条后半句进行分析,即为一条(不相容)选言命题:提出保证人,即保证人姓名(设为p)或者缴纳保证金,即保证金(设为q),即p⋁q,根据不相容选言命题的真值表(+为真,-为假):
表述为:当业务数据中既有保证人姓名又有保证金,或者同时两者都没有,则该业务数据错误。
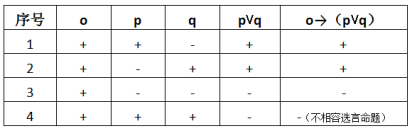
实际上,完整的来看该法条,可理解为充分条件的假言命题:如果强制措施为取保候审(设为o),则有保证人姓名或保证金。即:o→(p⋁q),亦可以用真值表表示:
然而上面的真值表并没有对所有情况都罗列,因为我们是以o为真作大前提,而实际上,o也可能为假。即当强制措施不为取保候审时,一样需要作出判断。这时我们发现该法条其实是充分必要条件的假言命题(当且仅当):无取保候审则无须保证人或保证金,有保证人或保证金一定对应取保候审。即:o↔(p⋁q)。据此我们可以得出,非取保候审时,保证人姓名或保证金为真,整个命题亦为假。完整的真值表应该如下:
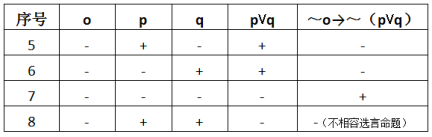
可见,从该例的法条中可以得到八种情况,其中有三种为真,五种为假,如果将这八种情况进行了判断,我们才可以说全面分析了相关的业务数据,各种问题都可以得到有效的发现。
二、在确定数据项和真值表的基础上,逐一比对在各类业务应用系统中收集的业务数据,构造出完全对应的业务数据真值表,直接吸收为监督模型的规则。
简言之,就是判断第一步中真值表里的数据项,是否能够在已有的系统中得到数据(已有系统可采集或已采集)。因为前述的数据项及真值表仅仅是理论中总结的情况,尽管已经做了取舍,但仍然不排除与实际工作中存在着较大的差距,具体问题可能表现为:
1.实际工作中的业务系统,并没有对一些数据项进行采集。如在“全国检察业务应用系统1.5”中,对刑事案件中的“被害人”信息并不采集。故我们就不能对以“被害人”为数据项的法律命题进行判断,真值表中有“被害人”相关项目的,即应予以舍弃不用。
2.某些数据项,尽管在特定的系统(或信息)中有所体现,但欠缺全面性、准确性。如在研究“专门人员是否超过任职期履职”时,我们发现,专门人员履职期限的信息,存在着公开公示不全面、任职日期有重合、参与履职日期不准确、是否连任不清楚等各种问题。此时,就要通过先期对相关信息进行梳理、识别,再来判断利用真值表分析的现实性与合理性。
3.应以谨慎乐观的态度对待通过OCR(光学字符识别)+NLP(自然语义识别)技术,从法律文书中提取所需要的数据。虽然ChatGPT的横空出世给语义识别带来一线曙光,且我们也应当将目光聚焦于运用大语言模型来实现法律文本的分析,但毕竟尚未有可复制可推广的成熟案例。而从起诉书、判决书等文书中自动提炼可靠的数据项和数据值,绝非一朝一夕之功。
如:希望通过从判决书中发现实施“托运”、“邮寄”、“寄递”或“快递”行为的人员主体信息,以发现漏犯的线索(或以绰号等关联不同案件,来查明涉案人员真实身份)。因文书内容结构、案件事实表述的千差万别,上述的关键字虽然可以提取,但却往往并不能准确提炼出这些行为的实施主体。
在解决了以上问题后,我们的真值表已经实现了将法律法规条文、已有业务数据完全转化为模型中所需的规则,在开展监督工作时,直接输入监督模型进行判断即可(如上述取保候审五种为假情形)。
三、结论
一边是庞杂的法律法规,一边是眼花缭乱的司法办案数据,通过抽丝剥茧、精益求精的法律逻辑方法提炼规则,可无缝对接法律监督模型,提高法律监督工作质效。
责任编辑:晓莉
声明:
本网站图片,文字之类版权申明,因为网站可以由注册用户自行上传图片或文字,本网站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。

征稿启事

投稿信箱:195024562@qq.com
品牌推荐更多>>

.jpg)
.jpg)



版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号