法安网内容检索
法安网内容检索
.jpg)
.jpg)
.jpg)
.jpg)
时间:2023-09-18 10:22:11 来源:刘沛宏
[法安导读] 一、问题的提出 现代社会中民众对正义的诉求更加直接化、可视化,往往将同案同判奉行为司法公正的最高标准。在科技不发达的纸质化时... 

一、问题的提出
现代社会中民众对正义的诉求更加直接化、可视化,往往将“同案同判”奉行为司法公正的最高标准。在科技不发达的纸质化时代,法官依靠个体经验及法学理论进行裁判,这种标准虽然存在,但一直处于隐性的“死火山”状态,究其原因在于民众没有更直观的途径去对比两个案件是否相同,以及相同案件是否得到了相同的审判,也没有更强大的动力去唤醒每个民众心中的“沉睡”的标准。但是在科技赋能的数字时代背景中,大数据、人工智能等数字技术的加持下,法官利用类案检索机制,为待决案件的裁判寻找到更多的参考,从个人经验主义迈向了集体思维逻辑,也为激活民众心中那个隐性的公正标准提供了有力的抓手。但是实践中,对于类案的识别的标准问题莫衷一是,学界也提出了各种的理论,在这些理论中,是否能够抽象出一套操作性强、简单明晰的标准成为了法官关注的重点。
二、阿克琉斯之踵:类案识别的困境
第一,识别标准众多,增加操作成本。对于两个案件是否可以被认定为同案在理论界提出了众多的解决方
案。比如有学者提出了判断类似案件的主要标准是争议点相似和关键事实相似,辅助标准是案由和行为后果相似。还有类似点、相似点的等标准。包括了对案件事实、法律适用及争议焦点等方面进行比对,来形成具体的评判标准。总体上来看,理论界对类案的研究有着丰案件事实厚的成果,为法官在司法实践中的判断提供了多重的理论支撑。但实际上法官在认定两个案件是否是同案时需要较强可操作性的标准。实践中反而会出现认定标准重叠的现象,法官在实践中的操作性成本就会不断增加,甚至会造成标准不明的现象。
第二,一旦矫枉过正,会出现“异案同判”。如果将类案检索作为一项义务强行附着在法官的身上,就会引起法官采取风险转移等方式来进行卸责,一旦矫枉过正就会带来过拟合的“异案同判”之风险,偏离了类案检索机制设立最初为矫正“同案异判”设定的路线。在大数据、人工智能技术的辅助下,类案检索为法官裁判结论的合理性进行了华丽的“包装”。成为了法官证明裁判结果合法性的注脚,检索的案件随时可以被替换只为寻找到与自己裁判思路匹配的“同案”。由于类案检索机制功能在实践中出现异化及越位,甚至在比对的过程中,牵强附会、生搬硬套的风险会陡增。同时也会造成法官的“规则依赖”倾向。
三、源头治理:同案的识别路径及运用的风险化解
1. 探索建立实体程序双重识别标准
第一,实体标准。实践中应以争议焦点来作为核心确定比较维度。正如张骐教授提出判断类似案件的主要标准是争议点相似和关键事实相似,辅助标准是案由和行为后果相似。争议焦点的总结和归纳就是法官对审理对象的固定,将案件事实及法律适用化繁为简、化整为零的过程。因此通过确定争议焦点就能够排除那些其他可以被替换且不影响实质的要素,而这种实质性要素被学者认为就是具有法律上的相似性的关键事实或者实质性事实。在明确了争议焦点及关键事实的基本概念后,下一步就是应当如何锁定关键事实,并通过关键事实及争议焦点进行类案识别?(如图1)首先,对于关键是是的判断一方面以法律规范的要件事实作为判断的基础,另一方面法官需要结合裁判理由及争议焦点对关键事实进行淬炼,二者结合总结出关键事实。其次,运用“提取公因式”及价值判断的方式将两个案件中共同点或者相似点及不同点进行提取比较,剔除不同点。再次,在争议焦点及规范的要件事实的指引下深耕出本案与二者相关的相似性和相关的不同性。以相关相似性与相关不同性的分量比例来判断两个案件是否为类案。最后,综合判断是否属于类案。要以规范目的及刑法中的一般原则、当下的刑事政策等方面来对两个案件是否构成类案进行实质性判断。
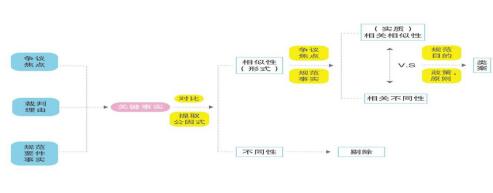
(图1 关键事实及类案的识别示意图)
在司法实践中人工智能无法完全取代法官完成此项评判工作。因为从本质上看,类案判断的背后是价值的判断,也体现了人类共同的理性,法官对类案的识别是携带着价值标准一直穿梭于事实与规范之间。但人工智能并非在此过程中一无是处,具体而言分为以下几步(如图2):首先系统自动进行案件类型的判定。人工智能以案由进行分类,以刑事案件为例,又可以按照罪名进行分类。一旦将起诉书电子化录入系统后,人工智能就可以通过模块化方式直接关联与起诉罪名相关的案件。其次进行争议焦点识别与判断。这需要法官结合自身的办案经验与案件的具体事实、庭审过程中控辩双方的争议情况来进行综合的人工判断、总结与归纳。再次根据总结归纳的争议焦点进行类案检索并进行关键事实的相似度比对。类案检索平台在这个环节可以充分发挥人工智能算法及大数据的优势地位,在法官的检索方式支配下,完成类案的结果筛选。法官依据筛选的结果来进行对关键事实进行人工比对。最后按照裁判规则进行最后的结论认定。要确定参照的级别,人工智能可以将案件级别进行分类,在检索的结果中予以体现,法官根据规定及政策、价值等多方考虑作出最终的判断。
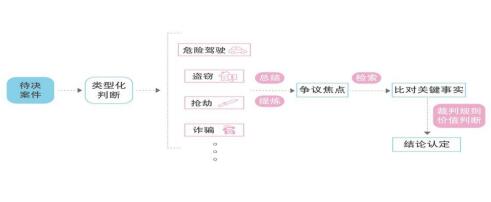
(图2 人工智能在类案识别中的应用)
程序标准。上述实体认定标准很有可能因为法官个体的差异带来不确定性,因此可以借助程序标准对实体标准予以辅助判断。《关于统一法律适用加强类案检索的指导意见(试行)》第七、八两条的规定就形成了类案判断程序标准的雏形。即借助合议庭、专业委员会或审委会对法官应用类案检索机制的结果进行认定,这种方式就是通过程序标准来辅助实体标准的认定。这样的方式体现了认定标准的清晰化,可操作性也相对较强,同时使法官个体的经验识别受制于法院集体认定的“多数理解”,可以有效避免本院内的裁判冲突。第二,至少能够在形式上保持了裁判结果的一致性,有利于本级法院的司法公信力的提升。
2.避免“过拟合”或“欠拟合”状态的出现
人工智能领域认为,当算法把训练样本学习“太好”的时候,很可能已经把训练样本自身的一些特点当做了所有潜在样本都会具有的一般性质,这样就会导致泛化性能的下降。与过拟合相对的就是“欠拟合”,这是说明人工智能的算法还没有达到训练要求。在类案检索机制中,如果一旦对同案同判矫枉过正,就会面临过拟合状态,体现在实践中就是“异案同判”,如果没有做到位或者检索质量过低,就会出现欠拟合情形。如图3所示,如果将A视为指导性案例或者其他类案,A周围的原点是待决案件,那么理想的状态是待决案件无限接近于A,而非与A重合,也非严重偏离。原因在于即便是类案,也会有差异性,也会受到其他法外因素的影响,不可能做到毫无差别的重合。要避免过拟合或欠拟合状态的发生,就要从结论的参照转向对过程的参照。说理论证是一份裁判文书的生命线,也是避免过拟合或欠拟合状态的最好说明书。法官在裁判的过程中,逻辑起点不应定位于结果的一致性,而应当转向从案件论证过程进行说明和权衡。
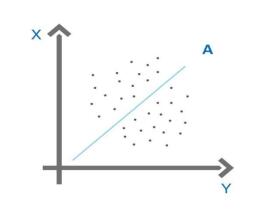
(图3 过拟合或欠拟合状态)
四、结语
民众对实质正义及形式正义的追求,促使着法官在裁判案件的过程中要参照先例,人工智能及大数据等数字化技术的额发展也为法官获得更多的先例提供了空前未有的便利条件,为类案检索机制打下了坚实的技术基础。类案检索机制也随着科技的突飞猛进在司法实践中日益升温。在此机制助力下,全国各地区法院的判决都有可能具有“可以参照”的效力,尤其是在数字化时代,大数据为法律人找到了寻找更多案例的方式,甚至突破了法律人适用的藩篱,该机制具有的友好性可以让每个普通民众享受指尖上的预测和监督权利。
责任编辑:广汉
声明:
本网站图片,文字之类版权申明,因为网站可以由注册用户自行上传图片或文字,本网站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。

征稿启事

投稿信箱:195024562@qq.com
品牌推荐更多>>

.jpg)
.jpg)



版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号