

也可直接联系我们
方式一 拨打报名热线或邮件咨询:
电话: 010-67046081
邮件: 195024562@qq.com
方式二 填写参会确认表
表单下载: 下载
发邮件至: 195024562@qq.com
或传真至: 010-67046081
无奖竞答:下面这段文字中一共出现几位角色?

“困难的”说话人角色分离任务
“难”在口杂:多人语音交叠,且对话风格随意;
“难”在干扰:远场混响和噪声等真实环境干扰;
“难”在考核:评价指标严苛,说话人边界容忍度为0。
比赛共有两种任务类型:
DIHARD系列赛持续吸引了国内外一流的研究机构,包括约翰霍普金斯大学、布尔诺理工大学、昆山杜克大学、南加州大学、牛津大学等顶尖团队。科大讯飞联合中国科大语音及语言信息处理国家工程实验室杜俊副教授团队(USTC-NELSLIP)在四个任务排行榜上包揽所有指标第一名,摘得桂冠。
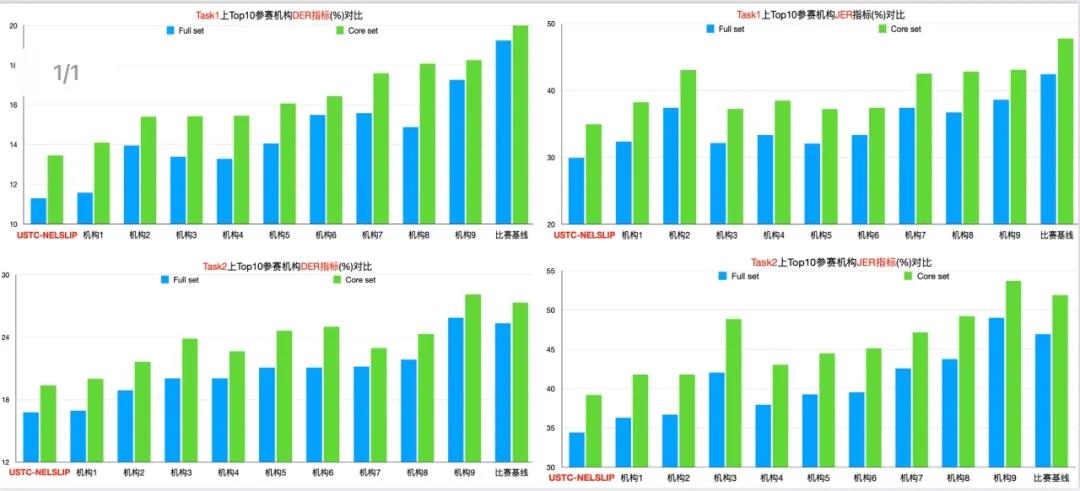
【注释】DER:Diarization Error Rate : 说话人分离错误率,分离错误的时长占总体有效语音时长的百分比;JER: Jaccard Error Rate: 雅卡尔错误率,所有单个说话人分离错误率的平均。
创新性地将说话人角色分离问题当做语音分离问题来解决,使用端到端语音分离模型,直接处理混合语音,将不同角色的语音信号分开,避免了重叠语音段的检测和标记问题。
将角色标签的指派问题,转化为目标说话人的语音检测问题。利用通过传统聚类方法(或语音分离方法)得到的说话人角色先验,绑定语音检测模型后,直接对每个单独说话人进行存在概率估计,使得每个说话人均能被精准地针对性处理。
创新性提出迭代式说话人估计算法。相比于直接给出估计结果,该策略针对每个角色目标,结合上述各种方法,不断提取说话人角色特性,并优化当前模型。最终建立起多层次多阶段的处理方法,使得系统能够逐渐地建立起对当前会话中每个说话人的感知能力。
最终,所提交系统在复杂场景数据上展现出了较好的鲁棒性,大幅提升了整体角色分离的性能,在比赛的所有数据集合、所有指标下均斩获第一名的好成绩。
【责任编辑:张伟】
版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号








